Based on:
M. von Looz, H. Meyerhenke: Querying Probabilistic Neighborhoods in Spatial Data Sets Efficiently. To appear in Proc. 27th International Workshop on Combinatorial Algorithms (IWOCA 2016), Springer-Verlag. Preprint available on arxiv.
Range queries in spatial datasets are a well-established problem with applications in image processing, computer vision and numerous physical simulations.
In some cases, the neighborhood of a given query point is probabilistic: The chance that a connection between two wireless nodes can be established depends on their distance, as does the probability that an infectious disease spreads between an infectious and a susceptible person. \(\newcommand{\dist}{\operatorname{dist}}\)
To handle these random fluctuations, we define the notion of a probabilistic neighborhood:
Let \(P\) be a set of \(n\) points in \(\mathbb{R}^d\), \(q \in \mathbb{R}^d\) a query point, \(\dist\) a distance metric,
and \(f : \mathbb{R}^+ \rightarrow [0,1]\) a non-increasing function.
Then a point \(p \in P\) belongs to the probabilistic neighborhood \(N(q, f)\) of \(q\) with respect to \(f\)
with probability \(f(\dist(p,q))\).
We envision applications in facility location, sensor networks, and
other scenarios where a connection between two entities becomes less likely with
increasing distance. A straightforward query algorithm would determine a probabilistic neighborhood in \(\Theta(n\cdot d)\) time by probing each point in \(P\).
Interactive Probabilistic Neighborhood query over 300 random points, the query point \(q\) is set to the position of the mouse cursor.
Points are colored according to the probability that they are included in the neighborhood. Blue represents a high probability, white a probability of zero.
The probability that a given point at distance \(d \) is included is \(e^{-d/40 pixel} \). Clicking executes a probabilistic range query and colors the neighborhood points in red.
Query Algorithm
In our recent work, we present a query algorithm for the planar case with a time complexity of \(O((|N(q,f)| + \sqrt{n})\log n)\) with high probability.
To achieve this sublinear complexity, we use a modified quadtree to sample neighbor candidates among the points and only evaluate the probability function \(f\) for these candidates. The probability that a point is a candidate depends on the distance of its quadtree cell to the query point.
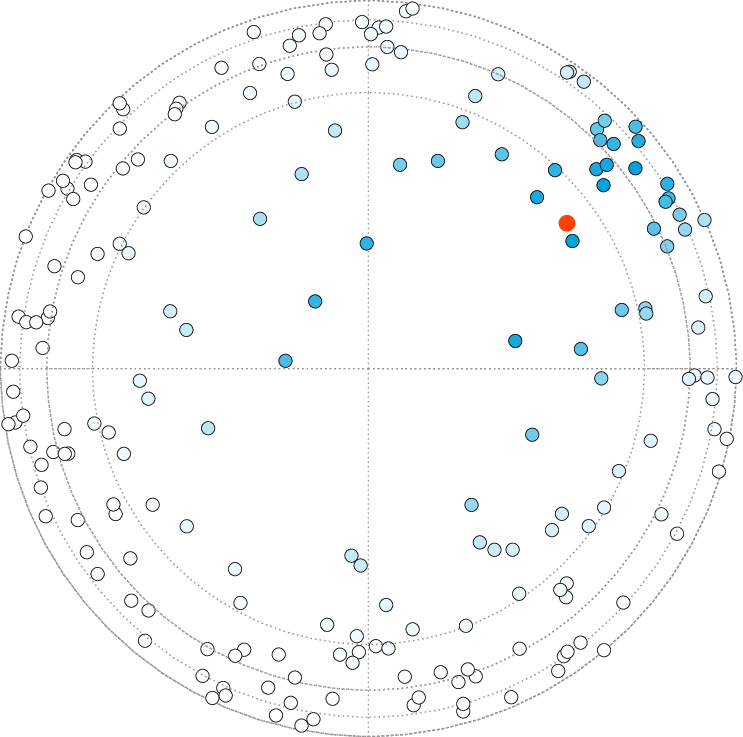
Query over 200 points in a polar hyperbolic quadtree, with the query point \(q\) marked in red and \(f(d) := 1/(e^{(d-7.78)}+1)\).
Points are colored according to the probability that they are included in the result. Blue represents a high probability, white a probability of zero.
This distance from a quadtree cell to the query point \(q \) gives a lower bound for the distance between any point \(p\) within the cell and \(q\).
Given that the function \( f\) is non-increasing, this also gives an upper bound for the probability that a given point within the quadtree cell is included in the probabilistic neighborhood.
Visualization of the data structure used in the previous picture.
Quadtree nodes are colored according to the upper probability bound for points contained in them.
The color of a quadtree node \(c\) is the darkest possible shade (dark = high probability) of any point contained in the subtree rooted at \(c\).
Each node is marked with the number of points in its subtree.
The algorithm traverses the quadtree and samples neighbor candidates and neighbors within the leaves.
Applications
As practical proofs of concept we use two applications, one in the Euclidean and one in the hyperbolic plane.
As application for the Euclidean plane, we simulate a disease progression using population data from Germany:
The speedup factor against a straightforward implementation is at least one order of magnitude even for modest datasets.
For the hyperbolic plane, we use the probabilistic neighborhood query to quickly generate hyperbolic random graphs with a connectivity decay function.
Preprint
For more information, a preprint is available on arxiv. The implementation will be made available after publication of the paper.